
This page is maintained by Aaron Leventhal and by the Mozilla Accessibility Community. Feedback and constructive suggestions are encouraged.
1. Intro
This document is for people who wish to understand the architecture of Mozilla's accessibility API module, which provides support for platform accessibility APIs. Accessibility APIs are used by 3rd party software like screen readers, screen magnifiers, and voice dictation software, which need information about document content and UI controls, as well as important events like changes of focus. Mozilla supports two accessibility APIs: Microsoft Active Accessibility (MSAA) on Windows and Accessibility Tool Kit (ATK) on Linux and Unix. We do not currently support the Carbon accessibility model for Apple's OS X.
Please note, the documentation for implementing an MSAA server has moved. You may also wish to read Gecko Info for Windows Accessibility Vendors, a primer for vendors of 3rd party accessibility software, on how MSAA clients can utilize Gecko's support. If you're interested in Linux or UNIX accessibility, check out Mozilla's ATK project page.
Readers of this document should be familiar with interfaces, the W3C DOM, XUL and the concept of a layout object tree.
2. Accessible Nodes and Interfaces
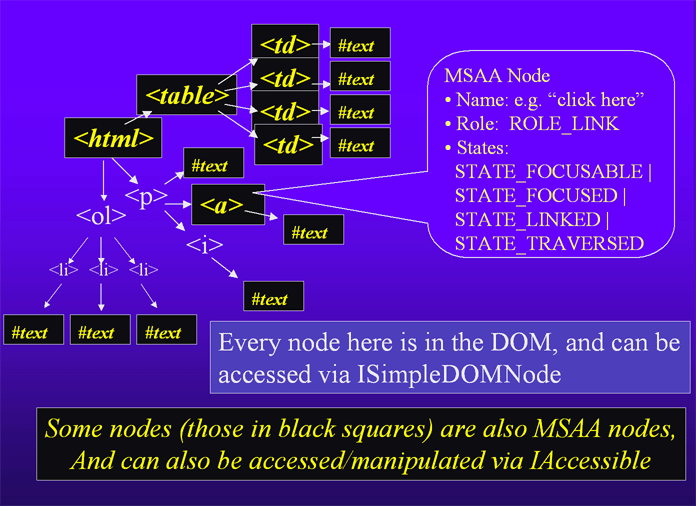
Every node in the DOM tree could be important to 3rd party assistive technology. Accessibility APIs on each operating system have built-in assumptions about what is the most important information, and how an accessibility server like Mozilla should use the API's programmatic interfaces to expose this information to an accessibility client (the assistive technology). Each platform's accessibility API has made different assumptions, although there are a number of common characteristics. For example, they all expose an accessible name, or text representation, of each object, and they all use an enumerated integer value from a finite list, to expose the role of an object. Examples of accessible role constants are ROLE_BUTTON, ROLE_CHECKBOX and ROLE_LIST, although they can have slightly different names and values in each API. In general, the accessibility APIs use similar concepts, but use different method, constant and interfaces names.
Given that there is a fair amount of commonality between accessibility API toolkits, it made sense to write of the code in a cross platform manner, and then deal with the platform differences on a consistent manner. The shared code makes itself available to the toolkit-specific code via generic XPCOM interfaces that return information about objects we want to expose. All focusable nodes, tables and text have accessibility interfaces. We call these objects "accessible nodes". Each of these accessible nodes supports at minimum the generic cross-platform accessibility interface nsIAccessible (which provides a text name, enumerated role identifier and a set of state flags) and sometimes additional interfaces. For example, tables support nsIAccessibleTable, text supports nsIAccessibleText and edit boxes support nsIEditableText., although this code has been moved into the ATK specific directories because it is not currently used in Windows. We will not rule out the possibility of supporting some of the rich ATK interfaces on Windows.
The toolkit-specific classes then use these XPCOM interfaces to gather information about the objects they want to expose, make any necessary changes, and then expose the information using Microsoft COM on Windows, or through GTK2's ATK API's on Linux and Unix.
The assistive technology can then use this information in a number of ways. It can read in an entire document at once, look only pieces of a document related to recent events, or traverse the accessibility object model based on screen position.
Accessible Tree Contains Only a Subset of Nodes from the DOM Tree
Not all DOM nodes are exposed through accessibility API toolkits -- only those objects deemed important by the developers of the toolkit. Mozilla keeps around its own tree of accessibility objects, which parallels the DOM tree, but is not a full representation.
Above: a diagram showing that the MSAA tree is a subset of the DOM tree. The situation for other accessibility APIs is similar.
The problem is, what happens if there are DOM nodes that the assistive technology vendors wants to know about, which are not exposed? Also, what if they want to get DOM information, like CSS rules, tag names and attributes, that MSAA's IAccessible does not provide?
On Windows, we solve this by supporting an additional interface beyond MSAA's IAccesible, for every DOM node. QueryInterface() can be used to switch between the two interfaces. If there is no MSAA node for a DOM node, pAccessible->QueryInterface(IID_IAccessible) will return null. In addition, some vendors had asked us to provide information and support for pieces of text smaller than a text node (i.e. a word), and Mozilla supports ISimpleDOMText for this purpose.
On ATK there is no such interface to get actual DOM information. Sun Microsystems, the maintainers of Mozilla's ATK support, believe the ATK is rich enough to provide everything the assistive technologies on their platform will need.
Accessibility API Module Directory Structure
General rules for the directory structure:
- Interfaces, both internally-used cross-platform and toolkit-specific interfaces exist in accessible/public.
- The implementations for each kind of object (document, text, table, edit box, button, etc.) exist in accessible/src.
- Code and interfaces for specific toolkits should go in the appropriate directoy. Toolkit specific implementations should have "Wrap" appended to the class name. For example, document specific code for each toolkit goes in nsDocAccessibleWrap: public nsDocAccessible.
| Directory | Purpose |
|---|---|
| accessible/public | common interfaces shared by all toolkits |
| accessible/public/msaa | Custom COM interfaces that we use to extend MSAA's IAccessible |
| accessible/public/atk | Internal XPCOM ATK interfaces |
| accessible/src/base | common implementations shared by HTML and XUL implementations |
| accessible/src/html/ | Document and HTML object implementations |
| accessible/src/xul/ | User interface and XUL object implementations |
| accessible/src/msaa/ | Windows implementations |
| accessible/src/atk/ | ATK implementations, may eventually be used on platforms other than Linux and UNIX |
| accessible/src/mac/ | Empty implementations of platform-specific classes for OS X. These implementatiosn may be filled later. |
| accessible/src/other/ | Empty implementations of platform-specific classes so that builds don't fail on platforms currently not-supported |
Where We Put Toolkit-Specific Code
Because ATK and MSAA are different accessibility API toolkits which share only about 75% of their code, there is a lot of toolkit-specific code that needs to live somewhere. In the past, this was accomplished through aggregation -- two separate trees of objects were kept, one in accessible/src and one in widget/src. However, because this would have caused a lot of difficulty when implementing the accessibility cache, the code was moved in to the "Wrap" classes in a source directory specific to each toolkit.
Classes with "Wrap" in the name, such as nsTextAccessibleWrap and nsDocAccessibleWrap, inherit from cross-platform classes of similar name without "Wrap" in them. They may override some methods, such as Init() and Shutdown(), and add other methods to support interfaces needed only by the given toolkit. For example, nsAccessibleWrap implements the methods in IAccessible, but because it is also an nsAccessible, it only needs to call the nsIAccessible methods in "this" to get at the information it needs.
Class Inheritence Diagram
View the Class Inheritence Diagram.
3. Accessible Tree Construction and Traversal
The accessible tree is constructed on demand. The first request for an accessible is usually the accessible for document in one of the open windows, and the code in widget/src/gtk2 or widget/src/windows must return this doc accessible. Even if a child accessible of the document is asked for first, the doc accessible will be created first, because it is needed to cache any accessibles created within it.
When the doc accessible is asked for, an event is fired which reaches the PresShell, which then uses the accessibility service singleton (nsIAccessibilityService) to create the doc accessible and return it back to the widget code. The reason that the doc accessible is not created directly in the widget code where it's needed is that the widget code has no knowledge what nsIDOMNode is associated with the current window's document object. There must be a document for the current widget (nsWindow/nsIWidget) for the pres shell to create a doc accessible for it.
One benefit of this approach is that accessibility.dll/libaccessibility.so does not need get loaded until the accessibility service gets used, and for most users it is never loaded.
All other accessibles for the individual objects are created on demand as well. The assistive technology can choose to get the entire tree by using a depth- or breadth- first search, it can choose to get accessibles only based on events like focus, or it can get the accessible at a given point on the screen. No matter how the assistive technology client requests the data, the accessible for a given node is only created once. We use the accessibility cache to retrieve accessibles that have already been created for a given dom node.
This tree traversal is accomplished via toolkit-specific calls which end up as calls into nsIAccessible methods GetAccParent(), GetAccNextSibling(), GetAccPreviousSibling(), GetAccFirstChild(), GetAccLastChild(), GetAccChildCount() and GetChildAt(childNum). The ATK has more convenience methods than MSAA does for traversal - for example it is possible to go straight to the accessible for a specific row and column of a table, using nsIAccessibleTable::CellRefAt().
The algorithm used to calculate the number of accessible children for an accessible node is expensive. We cannot assume that all of the accessible children will come from the direct children, grandchildren or even great-great-great-children of the current accessible's node. Therefore we have to iterate through the tree as if we were creating all of the accessible children, adding to the total as we go.
To make this less expensive, once the child count or any child of an accessible is asked for, both the child count and the children are calculated at the same time and then cached, so that we can avoid doing these expensive operations more than once.
The nsIAccessible GetAccBlah() traversal methods mentioned above all have default implementations in nsAccessible. These default implementations use a class called nsAccessibleTreeWalker to do the real work. The nsAccessibleTreeWalker walks both the DOM and anonymous content in the document, and asks nsIAccessibilityService::GetAccessible() for an accessible for each node. If it's in the cache, that is returned. XUL elements are checked for support of the nsIAccessibleProvider interface, which can return an accessible. HTML elements ask the node's primary frame for an accessible via nsIFrame::GetAccessible(). If nsnull is returned than the tree walker checks the next node, in depth first order.
Calling Sequence:
How an Accessible Node is Returned by nsIAccessible's Traversal Methods
operator new, which finally constructs the object.
Whether via nsIAccessibleProvider::GetAccessible() or nsIFrame::GetAccessible(), new accessibles are created by calling back to the accessibility service, and using a specific method for creating each type of accessible. For example, nsHTMLTableCellFrame::GetAccessible() will eventually call nsIAccessibilityService::CreateHTMLTableCellAccessible(), which uses |new nsHTMLTableCellAccessible(domNode, weakPresShell);
Special Exception: Traversal Overloading
In some cases the necessary accessible children are not in the DOM subtree for a node. This is the case for:
- nsHTMLImageAccessible: in MSAA an image accessible can have accessible children if it has an image map. The children are the image map areas, which are in a different part of the DOM tree.
- nsHTMLComboboxAccessible: an html combo box doesn't have a DOM node or anonymous content for its s textfield, button or list. In the future XBL form controls may be used, in which case there will be dom content for these sub-parts, and we will not need to override the traversal methods. That is why we don't need to override these traversal methods for nsXULComboboxAccessible (<menulist>).
- nsOuterDocAccessible: used for elements such as <iframe>, <browser> and <editor>, which spawn an entire new document, but don't actually have any child nodes in their own DOM.
- nsXULTreeAccessible: which does not have a DOM node for each tree item, a special interface is provided by the tree itself to get the text for each row, column in the tree.
In all of these accessible implementations we override nsIAccessible::GetAccChildCount(), ::GetAccFirstChild() and ::GetAccLastChild(). In this way we avoid the normal nsAccessibleTreeWalker traversal methods and create whatever child accessibles we want. When there is no DOM node for each accessible, as is the case for nsHTMLComboboxAccessible and nsXULTreeItemAccessible, we also need to override the Shutdown() method, so that the children get removed from memory when the parent is shutdown. In that case we also override ::GetAccNextSibling(), ::GetAccPreviousSibling() for the DOM-less children; otherwise they do not know how to find each other.
It is also useful to override these the child getters to return nothing, as we do in nsLeafAccessible, nsTextAccessible and other accessible implementations where we want to be sure to avoid children. Returning nothing for leaf and text objects also helps speed up tree construction and traversal.
4. Accessible Events
Accessible events are DOM events translated into the event mechanism of the given platform, using the enumerated event numbers listed in nsIAccessibleEventReceiver.idl. The accessibility client can find out what kind of event occurred as well as what accessible node the event occured on.
Table of Gecko Event to Accessible Event Translation
Accessible documents listen for DOM events on nodes within them, and consequently fire the appropriate accessible event. This happens in the HandleEvent() method.
Note: this chart is not complete, consult the HandleEvent() method to see the rest.
| Gecko Events (or callback) | Event Type | Accessibility Event |
|---|---|---|
| focus, select | Standard HTML DOM event | EVENT_FOCUS |
| DOMMenuItemActive, DOMMenuBarActive | Mozilla DOM | EVENT_FOCUS |
| DOMNodeInserted | W3C DOM Mutation event | EVENT_CREATE (ATK) EVENT_REORDER (MSAA) |
| DOMSubtreeModified | W3C DOM Mutation event | EVENT_REORDER |
| DOMNodeRemoved | W3C DOM Mutation event | EVENT_DESTROY (ATK) EVENT_REORDER (MSAA) |
| CheckboxStateChange, RadioStateChange | Mozilla DOM | EVENT_STATE_CHANGE |
| popupshowing | Mozilla DOM | EVENT_MENUSTART |
| popuphiding | Mozilla DOM | EVENT_MENUEND |
| nsDocAccessible::ScrollPositionDidChange(), then nsDocAccessible::ScrollTimerCallback() | nsIScrollPositonListener and nsITimer callbacks | EVENT_SCROLLINGEND (quick timer is used to determine when scrolling pauses or stops, to avoid extra events being fired) |
| nsDocAccessible::OnStateChange(), :nsDocAccessible:OnLocationChange() | nsIWebProgressListener callback | EVENT_STATE_CHANGE (MSAA) EVENT_REORDER (ATK) |
DOM Mutation Events - Multiple Uses
DOM mutation events are a great thing. They are fired by Gecko whenever nodes in the document are created, moved or changed. Common reasons for these mutations are web page scripts, and user actions in the editor.
We listen to DOM mutation events for several resons:
- To broadcast document changes to the assistive technology client. However, on Windows there are crash issues with the automatic Windows-generated versions of EVENT_CREATE and EVENT_DESTROY, so the MSAA client cannot listen to them. We fire the safer EVENT_REORDER in their place..
- To see what parts of the accessibility cache need to be invalidated. However, we are careful not to do this work for mutation events fired because the document is still loading.
Currently (as of May 2003), we do not yet use DOMAttrModied to listen to attribute changes on a node. We need to listen to some attribute changes because they might signal the need to invalidate parts of our cache; for example, if the name or href attribute on an anchor element changes, or the usemap attribute of an img changes. These cases are not very likely, but we should try to think of real-world scenarios where it might happen. If we do this, the code would go into nsDocAccessible::AttrModified().
Unique 32-bit Identifiers in MSAA
In MSAA, we must hand out a unique 32 bit child number for each target accessible with the event. To get this value we currently take the pointer to the DOM node, turn it into an integer, and then negate it. When the MSAA client calls back for the accessible node using AccessibleObjectFromEvent(), Windows asks our doc accessible for a child with that child ID. This is handled in in nsDocAccessibleWrap::get_accChild(), where we check for a negative child number and then use the accessibility cache to return the correct object.
5. Accessibility Cache
The accessibility module maintains a cache implemented as a series of hash tables -- one per document. The hash keys are the pointers to the DOM node for each accessible. In this way no accessible object should ever need to be created twice for any DOM node.
Why We Need Accessibility Cache
The accessibility cache has a number of purposes:
- Stability: because the Gecko DOM and layout teams want to avoid memory bloat where necessary, we could not afford to use 4 bytes on DOM or layout nodes to point back to accessible objects. Therefore, ownership is reversed -- accessible nodes own their dom objects. However, this creates instability when Mozilla wants to shut down but an assistive technology client still holds onto accessibles. These crashes occur when the assistive techology releases after some Gecko modules have already been unloaded, when the necessary destructors no longer exist in memory.
- Performance: by caching the accessible node for each DOM node in a hash table, we can hand back accessibles extremely quickly, and avoid recalculating and creating new accessibles every time one is requested for a certain DOM node. We also avoid calculating the children of an accessible twice, once for GetAccChildCount() and again when the specific children are requested.
- Events: we must ensure that the accessible for an event is not released before the accessible client has a chance to review its data. Also, MSAA clients need to access the event accessibles using the unique child ID we give it. When we get the child ID back, we can recreate the hash key needed to retrieve the accessible. Finally, because the MSAA client gets the same accessible for the event and for tree traversal each time, it can do comparisons with its own internal data model. For example, this allows the MSAA client to invalidate parts of its own cache or data model based on DOM mutation events.
Three Levels of the Accessibility Cache
There are three levels in the accessibility cache:
- Global cache of doc accessibles (gGlobalDocAccessibleCache), used to get the accessible for any document.
- Per-document cache of accessibles A cache in each nsDocAccessible (mAccessNodeCache), containing all of the accessible nodes created so far for each document.
- Member variables in nsAccessible that keep track of the number of children (mAccChildCount), the parent (mParent), the first child (mFirstChild) and the next sibling (mNextSibling). If mNextSibling equals the magic value DEAD_END_ACCESSIBLE (void*)1, then there are known to be no more siblings. If mNextSiblings == nsnull, then there could still be more siblings.
This architecture allows us to quickly wipe away an entire document's worth of cached nodes when a document goes away, simply by destroying the document accessible's cache.
However, it takes two steps to get a DOM node's cached accessible. We must first get the document accessible from the global cache for the node's document, and then use that document accessible's specific cache to check for an entry for the dom node. This is not much of a problem because it is still much faster than creating a new accessible every time. This two step process is implemented in nsAccessibilityService::GetCachedAccessible(domNode).
The member variables keeping track of the number of children, parent, first child and next sibling allow us to have instant traversal around accessible nodes that have already been visited.
Role of nsAccessNode
If you work mostly in the ATK sections of our accessibility module, you may wonder what the purpose of nsAccessNode is -- there are no ATK interfaces that use it. In fact, it exists because of our ISimpleDOMNode extension to MSAA, which we implement on nsAccessNodeWrap. ISimpleDOMNode is used by the assistive technology to get access to information about individual DOM nodes which may or may not be "accessible".
Because an nsAccessNode can point to any DOM node, even DOM nodes that are not "accessible", it may or may not also be an nsAccessible. In other words, the lowest common denominator for objects we must cache is nsAccessNode.
nsAccessNode::Init()
When nsAccessibilityService::GetAccessible() gets a newly created accessible, it calls nsIAccessNode::Init() on the new object, which will add this to the cache for the doc accessible. Each nsAccessNode contains the dom node and weak pres shell for the object. The weak pres shell is used to create a hash key to get the doc accessible from gGlobalDocAccessibleCache. The dom node pointer is used to create the new hash key and add the nsIAccessNode* into the document accessible's mAccessNodeCache.
The Init() method is also virtual, and many accessibles override it to do their own special initialization. If they do, they must also call their parent class' Init() method when finished.
nsAccessNode::Shutdown()
Shutdown() is used when the dom node for the given nsAccessNode/nsAccessible no longer exists. It can be called in a number of ways:
- In the destructor for nsWindow: when the document is destroyed, its window also goes away. If there is a newly loading document, it has its own separate window which has already been created and rendered into. In fact, for about a second two nsDocAccessible's exist for the same screen space - one for the old document about to be destroyed, and one for the loading document which hasn't been displayed yet. Side note: we do not fire the event indicating the new document is ready, until the new document is displayed.
- From a mutation event callback in nsDocAccessible, indicating that a node or subtree of nodes is changing or being removed. We iterate through all the dom nodes in the subtree, checking for nsIAccessNode entries in the cache for each dom node, shutting them down if they exist. This is better than just traversing the accessibles by using the member variables mFirstChild and mNextSibling, because that would miss nsAccessNode's that are not nsAccessible's.
- At program shutdown, when the nsAccessibilityService observes NS_XPCOM_SHUTDOWN_OBSERVER_ID, it iterates through the doc accessibles in gGlobalDocAccessibleCache and destroys all of the doc accessibles them.
Challenges of the Accessibility Cache
There are some tricky issues when dealing with the accessibility cache:
- Remaining valid: changes in a given document, or the destruction of documents must update or shutdown parts of the cache. We use DOM mutation events to listen for document changes, and invalidate the appropriate part of each cache. We must be careful: if the DOM mutation events are incomplete, then our cache will not be a correct mirror of the DOM. If we do not shut down nodes that go away, we cause more memory footprint than necessary.
- Accessibles with no DOM node: Some accessible children are generated by the accessible parent, because they have no DOM node. These accessibles cannot be shutdown by traversing the DOM, because their cache entry is not based on their DOM node. Therefore, the parent that generates these accessibles must also be responsible for shutting them down when their Shutdown() method is called. This is currently implemented for nsHTMLComboboxAccessible as wells as nsXULTreeAccessible.
6. Future Directions
In general, the Accessible API module work should now be coming to a conclusion. Unfortunately, we still are not fully working with any major screen reader, screen magnifier or voice dictation product on the market. We hope to change that soon, and are working with the major vendors (and Gnopernicus on Linux/UNIX) to achieve this.
In any case, for the moment the only plans on Windows are for minor bug fixes based on feedback from assistive technology vendors. On Linux and UNIX, there probably needs to be more work done on folding in with the new architecture (such as more use of the "Wrap" classes).
Something that could create more work would be a decision to support the Macintosh accessibility API, a new API being developed by Microsoft for future versions of Windows or some other new API developed for cross platform or small device use. Hopefully our general accessibility architecture will be able to support those APIs without major difficulties.
Join the Community
Live Chat
Both end users and developers are invited for discussion on the live IRC channel at irc.mozilla.org/#accessibility. Since this is a worldwide effort, there is always a good chance to find someone to chat with there, day or night.
Newsgroup and Mailing List
We have two discussion lists, which can be read via a newsgroup reader, as a mailing list or via Google groups.
| Purpose | Newsgroup | Mailing list | Google group |
|---|---|---|---|
| Developer discussion | mozilla.dev.accessibility | subscribe/unsubscribe | Google group |
| End user support | mozilla.support.accessibility | subscribe/unsubscribe | Google group |