
Most of the Mozilla code uses a C++ class hierarchy to pass string data, rather than using raw pointers. This guide documents the string classes which are visible to code within the Mozilla codebase (code which is linked into libxul).
Introduction
The string classes are a library of C++ classes which are used to manage buffers of wide (16-bit) and narrow (8-bit) character strings. The headers and implementation are in the xpcom/string directory. All strings are stored as a single contiguous buffer of characters.
The 8-bit and 16-bit string classes have completely separate base classes, but share the same APIs. As a result, you cannot assign a 8-bit string to a 16-bit string without some kind of conversion helper class or routine. For the purpose of this document, we will refer to the 16-bit string classes in class documentation. Every 16-bit class has an equivalent 8-bit class:
| Wide | Narrow |
| nsAString | nsACString |
| nsString | nsCString |
| nsAutoString | nsAutoCString |
| etc... | |
The string classes distinguish, as part of the type hierarchy, between strings that must have a null-terminator at the end of their buffer (ns[C]String) and strings that are not required to have a null-terminator (nsA[C]String). nsA[C]String is the base of the string classes (since it imposes fewer requirements) and ns[C]String is a class derived from it. Functions taking strings as parameters should generally take one of these four types.
In order to avoid unnecessary copying of string data (which can have significant performance cost), the string classes support different ownership models. All string classes support the following three ownership models dynamically:
- reference counted, copy-on-write, buffers (the default)
- adopted buffers (a buffer that the string class owns, but is not reference counted, because it came from somewhere else)
- dependent buffers, that is, an underlying buffer that the string class does not own, but that the caller that constructed the string guarantees will outlive the string instance
In addition, there is a special string class, ns[C]AutoString, that additionally contains an internal 64-unit buffer (intended primarily for use on the stack), leading to a fourth ownership model:
- storage within an auto string's stack buffer
Auto strings will prefer reference counting an existing reference-counted buffer over their stack buffer, but will otherwise use their stack buffer for anything that will fit in it.
There are a number of additional string classes:
- Classes which exist primarily as constructors for the other types, particularly
nsDependent[C]StringandnsDependent[C]Substring. These types are really just convenient notation for constructing anns[C]S[ubs]tringwith a non-default ownership mode; they should not be thought of as different types. nsLiteral[C]Stringwhich should rarely be constructed explicitly but usually through the""_nsandu""_nsuser-defined string literals.nsLiteral[C]Stringis trivially constructible and destructible, and therefore does not emit construction/destruction code when stored in statics, as opposed to the other string classes.
The Major String Classes
The list below describes the main base classes. Once you are familiar with them, see the appendix describing What Class to Use When.
nsAString/nsACString: the abstract base class for all strings. It provides an API for assignment, individual character access, basic manipulation of characters in the string, and string comparison. This class corresponds to the XPIDLAStringparameter type. nsAString is not necessarily null-terminated.nsString/nsCString: builds onnsAStringby guaranteeing a null-terminated storage. This allows for a method (.get()) to access the underlying character buffer.
The remainder of the string classes inherit from either nsAString or nsString. Thus, every string class is compatible with nsAString.
Since every string derives from nsAString (or nsACString), they all share a simple API. Common read-only methods:
.Length()- the number of code units (bytes for 8-bit string classes andchar16_ts for 16-bit string classes) in the string..IsEmpty()- the fastest way of determining if the string has any value. Use this instead of testingstring.Length== 0.Equals(string)- TRUE if the given string has the same value as the current string.
Common methods that modify the string:
.Assign(string)- Assigns a new value to the string..Append(string)- Appends a value to the string..Insert(string, position)- Inserts the given string before the code unit at position..Truncate(length)- shortens the string to the given length.
Complete documentation can be found in the Appendix.
Read-only strings
The const attribute on a string determines if the string is writable. If a string is defined as a const nsAString then the data in the string cannot be manipulated. If one tries to call a non-const method on a const string the compiler will flag this as an error at build time.
For example:
void nsFoo::ReverseCharacters(nsAString& str) {
...
str.Assign(reversedStr); // modifies the string
}
This should not compile, because you're assigning to a const class:
void nsFoo::ReverseCharacters(const nsAString& str) {
...
str.Assign(reversedStr);
}
As function parameters
For methods which are exposed across modules, use nsAString references to pass strings. For example:
// when passing a string to a method, use const nsAString& nsFoo::PrintString(const nsAString &str); // when getting a string from a method, use nsAString& nsFoo::GetString(nsAString &result);
The abstract classes are also sometimes used to store temporary references to objects. You can see both of these uses in Common Patterns, below.
The Concrete Classes - which classes to use when
The concrete classes are for use in code that actually needs to store string data. The most common uses of the concrete classes are as local variables, and members in classes or structs.
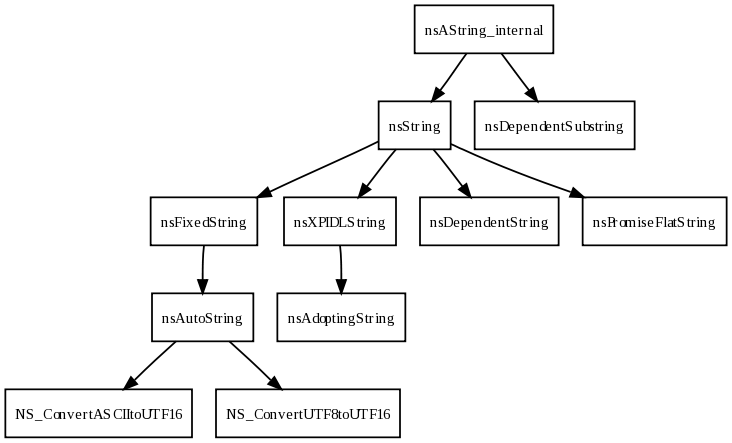
The following is a list of the most common concrete classes. Once you are familiar with them, see the appendix describing What Class to Use When.
nsString / nsCString- a null-terminated string whose buffer is allocated on the heap. Destroys its buffer when the string object goes away.nsAutoString / nsAutoCString- derived fromnsString, a string which owns a 64 code unit buffer in the same storage space as the string itself. If a string less than 64 code units is assigned to annsAutoString, then no extra storage will be allocated. For larger strings, a new buffer is allocated on the heap. If you want a number other than 64, use the templated typesnsAutoStringN/nsAutoCStringN. (nsAutoStringandnsAutoCStringare just typedefs fornsAutoStringN<64>andnsAutoCStringN<64>, respectively.)nsDependentString- derived fromnsString, this string does not own its buffer. It is useful for converting a raw string (const char16_t*orconst char*) into a class of typensAString. Note that you must null-terminate buffers used by to nsDependentString. If you don't want to or can't null-terminate the buffer, use nsDependentSubstring.nsPrintfCString- derived fromnsCString, this string behaves like annsAutoCString. The constructor takes parameters which allows it to construct a 8-bit string from aprintf-style format string and parameter list.
There are also a number of concrete classes that are created as a side-effect of helper routines, etc. You should avoid direct use of these classes. Let the string library create the class for you.
nsSubstringTuple- created via string concatenationnsDependentSubstring- created through SubstringnsPromiseFlatString- created throughPromiseFlatString()nsLiteral[C]String- created through the""_nsandu""_nsuser-defined literals
Of course, there are times when it is necessary to reference these string classes in your code, but as a general rule they should be avoided.
Iterators
Because Mozilla strings are always a single buffer, iteration over the characters in the string is done using raw pointers:
/**
* Find whether there is a tab character in `data`
*/
bool HasTab(const nsAString& data)
{
const char16_t* cur = data.BeginReading();
const char16_t* end = data.EndReading();
for (; cur < end; ++cur) {
if (char16_t('\t') == *cur)
return true;
}
return false;
}
Note that `end` points to the character after the end of the string buffer. It should never be dereferenced.
Writing to a mutable string is also simple:
/**
* Replace every tab character in `data` with a space.
*/
void ReplaceTabs(nsAString& data)
{
char16_t* cur = data.BeginWriting();
char16_t* end = data.EndWriting();
for (; cur < end; ++cur) {
if (char16_t('\t') == *cur)
*cur = char16_t(' ');
}
}
You may change the length of a string via SetLength(). Note that Iterators become invalid after changing the length of a string:
/**
* Replace every tab character in `data` with four spaces.
*/
void ReplaceTabs2(nsAString& data)
{
int len = data.Length();
char16_t *cur = data.BeginWriting();
char16_t *end = data.EndWriting();
// Because `cur` may change during the loop, track the position
// within the string.
int pos = 0;
while (cur < end) {
if (char16_t('\t') != *cur) {
++pos;
++cur;
} else {
len += 3;
data.SetLength(len);
// After SetLength, read `cur` and `end` again
cur = data.BeginWriting() + pos;
end = data.EndWriting();
// move the remaining data over
if (pos < len - 1)
memmove(cur + 4, cur + 1, (len - 1 - pos) * sizeof(char16_t));
// fill the tab with spaces
*cur = char16_t(' ');
*(cur + 1) = char16_t(' ');
*(cur + 2) = char16_t(' ');
*(cur + 3) = char16_t(' ');
pos += 4;
cur += 4;
}
}
}
If a string buffer becomes smaller while writing it, use SetLength to inform the string class of the new size:
/**
* Remove every tab character from `data`
*/
void RemoveTabs(nsAString& data)
{
int len = data.Length();
char16_t* cur = data.BeginWriting();
char16_t* end = data.EndWriting();
while (cur < end) {
if (char16_t('\t') == *cur) {
len -= 1;
end -= 1;
if (cur < end)
memmove(cur, cur + 1, (end - cur) * sizeof(char16_t));
} else {
cur += 1;
}
}
data.SetLength(len);
}
Note that using BeginWriting() to make a string longer is not OK. BeginWriting() must not be used to write past the logical length of the string indicated by EndWriting() or Length(). Calling SetCapacity() before BeginWriting() does not affect what the previous sentence says. To make the string longer, call SetLength() before BeginWriting() or use the BulkWrite() API described below.
Bulk Write
BulkWrite() allows capacity-aware cache-friendly low-level writes to the string's buffer.
Capacity-aware means that the caller is made aware of how the caller-requested buffer capacity was rounded up to mozjemalloc buckets. This is useful when initially requesting best-case buffer size without yet knowing the true size need. If the data that actually needs to be written is larger than the best-case estimate but still fits within the rounded-up capacity, there is no need to reallocate despite requesting the best-case capacity.
Cache-friendly means that the zero terminator for C compatibility is written after the new content of the string has been written, so the result is a forward-only linear write access pattern instead of a non-linear back-and-forth sequence resulting from using SetLength() followed by BeginWriting().
Low-level means that writing via a raw pointer is possible as with BeginWriting().
BulkWrite() takes four arguments: The new capacity (which may be rounded up), the number of code units at the beginning of the string to preserve (typically the old logical length), a boolean indicating whether reallocating a smaller buffer is OK if the requested capacity would fit in a buffer that's smaller than current one, and a reference to an nsresult for indicating failure on OOM. (Don't access the return value if the nsresult indicates failure. Unfortunately mozilla::Result is not versatile enough to be used here.)
BulkWrite() returns a mozilla::BulkWriteHandle<T>, where T is either char or char16_t. The actual writes are performed through this handle. You must not access the string except via the handle until you call Finish() on the handle in the success case or you let the handle go out of scope without calling Finish() in the failure case, in which case the destructor of the handle puts the string in a mostly harmless but consistent state (containing a single REPLACEMENT CHARACTER if a capacity greater than 0 was requested, or in the char case if the three-byte UTF-8 representation of the REPLACEMENT CHARACTER doesn't fit, an ASCII SUBSTITUTE).
mozilla::BulkWriteHandle<T> autoconverts to a writable mozilla::Span<T> and also provides explicit access to itself as Span (AsSpan()) or via component accessors named consistently with those on Span: Elements() and Length() the latter is not the logical length of the string but the writable length of the buffer. The buffer exposed via these methods includes the prefix that you may have requested to be preserved. It's up to you to skip past it so as to not overwrite it.
If there's a need to request a different capacity before you are ready to call Finish(), you can call RestartBulkWrite() on the handle. It takes three arguments that match the first three arguments of BulkWrite(). It returns mozilla::Result<mozilla::Ok, nsresult> to indicate success or OOM. Calling RestartBulkWrite() invalidates previously-obtained span, raw pointer or length.
Once you are done writing, call Finish(). It takes two arguments: the new logical length of the string (which must not exceed the capacity retuned by the Length() method of the handle) and a boolean indicating whether it's OK to attempt to reallocate a smaller buffer in case a smaller mozjemalloc bucket could accommodate the new logical length.
Helper Classes and Functions
Converting Cocoa strings
Use mozilla::CopyCocoaStringToXPCOMString() in mozilla/MacStringHelpers.h to convert Cocoa strings to XPCOM strings.
Searching strings - looking for substrings, characters, etc.
FindInReadable() is the replacement for the old string.Find(..). The syntax is:
PRBool FindInReadable(const nsAString& pattern,
nsAString::const_iterator start, nsAString::const_iterator end,
nsStringComparator& aComparator = nsDefaultStringComparator());
To use this, start and end should point to the beginning and end of a string that you would like to search. If the search string is found, start and end will be adjusted to point to the beginning and end of the found pattern. The return value is PR_TRUE or PR_FALSE, indicating whether or not the string was found.
An example:
const nsAString& str = GetSomeString();
nsAString::const_iterator start, end;
str.BeginReading(start);
str.EndReading(end);
constexpr auto valuePrefix = u"value="_ns;
if (FindInReadable(valuePrefix, start, end)) {
// end now points to the character after the pattern
valueStart = end;
}
Checking for Memory Allocation failure
The String classes now use infallible memory allocation, so you do not need to check for success when allocating/resizing "normal" strings.
Most of the functions that modify Strings (Assign(), SetLength(), etc) also have a version that takes a "mozilla::fallible_t" parameter. These versions return 'false' instead of aborting if allocation fails . Use them when creating/allocating Strings which may be very large, and which the program could recover from if the allocation fails.
Getting a char * buffer from a String
You can access a String's internal buffer using the iterator methods. The String retains ownership over the buffer at all times.
In other words, there is no way to "grab" the internal char * from a String, i.e. have the string "forget" about it and hand off ownership to other code. Sorry.
If you wish to make a copy of a String into a new character buffer (char16_t*char*), the preferred way is to allocate it with one of the following methods:
char16_t* ToNewUnicode(nsAString&)char16_t*buffer from annsAString.char *ToNewCString(nsACString&)- Allocates achar*buffer from annsACString. Note that this method will also work on nsAStrings, but it will do an implicit lossy conversion. This function should only be used if the input is known to be strictly ASCII. Often a conversion to UTF-8 is more appropriate. SeeToNewUTF8Stringbelow.char* ToNewUTF8String(nsAString&)- Allocates a newchar*buffer containing the UTF-8 encoded version of the given nsAString. See Unicode Conversion for more details and for better ways that don't require you to manage the memory yourself.
These methods return a buffer allocated using XPCOM's allocator instead of the traditional allocator (malloc, etc.). Outside of libxul you should use NS_Free to deallocate the result when you no longer need it, inside libxul free() is preferred..
Substrings (string fragments)
It is very simple to refer to a substring of an existing string without actually allocating new space and copying the characters into that substring. Substring() is the preferred method to create a reference to such a string.
void ProcessString(const nsAString& str) {
const nsAString& firstFive = Substring(str, 0, 5); // from index 0, length 5
// firstFive is now a string representing the first 5 characters
}
Unicode Conversion ns*CString vs. ns*String
Strings can be stored in two basic formats: 8-bit code unit (byte/char) strings, or 16-bit code unit (char16_t) strings. Any string class with a capital "C" in the classname contains 8-bit bytes. These classes include nsCString, nsDependentCString, and so forth. Any string class without the "C" contains 16-bit code units.
A 8-bit string can be in one of many character encodings while a 16-bit string is always in potentially-invalid UTF-16. (You can make a 16-bit string guaranteed-valid UTF-16 by passing it to EnsureUTF16Validity().) The most common encodings are:
- ASCII - 7-bit encoding for basic English-only strings. Each ASCII value is stored in exactly one byte in the array with the most-significant 8th bit set to zero.
- UCS2 - 16-bit encoding for a subset of Unicode, BMP. The Unicode value of a character stored in UCS2 is stored in exactly one 16-bit
char16_tin a string class. - UTF-8 - 8-bit encoding for Unicode characters. Each Unicode characters is stored in up to 4 bytes in a string class. UTF-8 is capable of representing the entire Unicode character repertoire, and it efficiently maps to UTF-32. (Gtk and Rust natively use UTF-8.)
- UTF-16 - 16-bit encoding for Unicode storage, backwards compatible with UCS2. The Unicode value of a character stored in UTF-16 may require one or two 16-bit
char16_ts in a string class. The contents ofnsAStringalways has to be regarded as in this encoding instead of UCS2. UTF-16 is capable of representing the entire Unicode character repertoire, and it efficiently maps to UTF-32. (Win32 W APIs and Mac OS X natively use UTF-16.) - Latin1 - 8-bit encoding for the first 256 Unicode code points. Used for HTTP headers and for size-optimized storage in text node and SpiderMonkey strings. Latin1 converts to UTF-16 by zero-extending each byte to a 16-bit code unit. Note that this kind of "Latin1" is not available for encoding HTML, CSS, JS, etc. Specifying
charset=latin1means the same ascharset=windows-1252. Windows-1252 is a similar but different encoding used for interchange.
In addition, there exist multiple other (legacy) encodings. The Web-relevant ones are defined in the Encoding Standard. Conversions from these encodings to UTF-8 and UTF-16 are provided by mozilla::Encoding. Additonally, on Windows the are some rare cases (e.g. drag&drop) where it's necessary to call a system API with data encoded in the Windows locale-dependent legacy encoding instead of UTF-16. In those rare cases, use MultiByteToWideChar/WideCharToMultiByte from kernel32.dll. Do not use iconv on *nix. We only support UTF-8-encoded file paths on *nix, non-path Gtk strings are always UTF-8 and Cocoa and Java strings are always UTF-16.
When working with existing code, it is important to examine the current usage of the strings that you are manipulating, to determine the correct conversion mechanism.
When writing new code, it can be confusing to know which storage class and encoding is the most appropriate. There is no single answer to this question, but the important points are:
- Surprisingly many strings are very often just ASCII. ASCII is a subset of UTF-8 and is, therefore, efficient to represent as UTF-8. Representing ASCII as UTF-16 bad both for memory usage and cache locality.
- Rust strongly prefers UTF-8. If your C++ code is interacting with Rust code, using UTF-8 in nsACString and merely validating it when converting to Rust strings is more efficient than using nsAString on the C++ side.
- Networking code prefers 8-bit strings. Networking code tends to use 8-bit strings: either with UTF-8 or Latin1 (byte value is the Unicode scalar value) semantics.
- JS and DOM prefer UTF-16. Most Gecko code uses UTF-16 for compatibility with JS strings and DOM string which are potentially-invalid UTF-16. However, both DOM text nodes and JS strings store strings that only contain code points below U+0100 as Latin1 (byte value is the Unicode scalar value).
- Windows and Cocoa use UTF-16. Windows system APIs take UTF-16. Cocoa NSString is UTF-16.
- Gtk uses UTF-8. Gtk APIs take UTF-8 for non-file paths. In the Gecko case, we support only UTF-8 file paths outside Windows, so all Gtk strings are UTF-8 for our purposes though file paths received from Gtk may not be valid UTF-8.
To assist with ASCII, Latin1, UTF-8, and UTF-16 conversions, there are some helper methods and classes. Some of these classes look like functions, because they are most often used as temporary objects on the stack.
Short zero-terminated ASCII strings
If you have a short zero-terminated string that you are certain is always ASCII, use these special-case methods instead of the conversions described in the later sections.
- If you are assigning an ASCII literal to an
nsACString, useAssignLiteral(). - If you are assigning a literal to an
nsAString, useAssignLiteral()and make the literal au""literal. If the literal has to be a""literal (as opposed tou"") and is ASCII, still useAppendLiteral(), but be aware that this involves a run-time inflation. - If you are assigning a zero-terminated ASCII string that's not a literal from the compiler's point of view at the call site and you don't know the length of the string either (e.g. because it was looked up from an array of literals of varying lengths), use
AssignASCII().
UTF-8 / UTF-16 conversion
NS_ConvertUTF8toUTF16(const nsACString&) - a nsAutoString subclass that converts a UTF-8 encoded nsACString or const char* to a 16-bit UTF-16 string. If you need a const buffer, you can use the char16_t*.get() method. For example:
/* signature: void HandleUnicodeString(const nsAString& str); */
object->HandleUnicodeString(NS_ConvertUTF8toUTF16(utf8String));
/* signature: void HandleUnicodeBuffer(const char16_t* str); */
object->HandleUnicodeBuffer(NS_ConvertUTF8toUTF16(utf8String).get());
NS_ConvertUTF16toUTF8(const nsAString&) - a nsAutoCString which converts a 16-bit UTF-16 string (nsAString) to a UTF-8 encoded string. As above, you can use .get() to access a const char* buffer.
/* signature: void HandleUTF8String(const nsACString& str); */ object->HandleUTF8String(NS_ConvertUTF16toUTF8(utf16String)); /* signature: void HandleUTF8Buffer(const char* str); */ object->HandleUTF8Buffer(NS_ConvertUTF16toUTF8(utf16String).get());
CopyUTF8toUTF16(const nsACString&, nsAString&) - converts and copies:
// return a UTF-16 value
void Foo::GetUnicodeValue(nsAString& result) {
CopyUTF8toUTF16(mLocalUTF8Value, result);
}
AppendUTF8toUTF16(const nsACString&, nsAString&) - converts and appends:
// return a UTF-16 value
void Foo::GetUnicodeValue(nsAString& result) {
result.AssignLiteral("prefix:");
AppendUTF8toUTF16(mLocalUTF8Value, result);
}
UTF8ToNewUnicode(const nsACString&, PRUint32* aUTF16Count = nsnull) - (avoid if possible) allocates and converts (the optional parameter will contain the number of 16-byte units upon return, if non-null):
void Foo::GetUTF16Value(char16_t** result) {
*result = UTF8ToNewUnicode(mLocalUTF8Value);
}
CopyUTF16toUTF8(const nsAString&, nsACString&) - converts and copies:
// return a UTF-8 value
void Foo::GetUTF8Value(nsACString& result) {
CopyUTF16toUTF8(mLocalUTF16Value, result);
}
AppendUTF16toUTF8(const nsAString&, nsACString&) - converts and appends:
// return a UTF-8 value
void Foo::GetUnicodeValue(nsACString& result) {
result.AssignLiteral("prefix:");
AppendUTF16toUTF8(mLocalUTF16Value, result);
}
ToNewUTF8String(const nsAString&) - (avoid if possible) allocates and converts:
void Foo::GetUTF8Value(char** result) {
*result = ToNewUTF8String(mLocalUTF16Value);
}
Latin1 / UTF-16 Conversion
The following should only be used when you can guarantee that the original string is ASCII or Latin1 (in the sense that the byte value is the Unicode scalar value; not in the windows-1252 sense). These helpers are very similar to the UTF-8 / UTF-16 conversion helpers above.
UTF-16 to Latin1 converters
These converters are very dangerous because they lose information during the conversion process. You should avoid UTF-16 to Latin1 conversions unless your strings are guaranteed to be Latin1 or ASCII. (In the future, these conversions may start asserting in debug builds that their input is in the permissible range.) If the input is actually in the Latin1 range, each 16-bit code unit in narrowed to an 8-bit byte by removing the high half. Unicode code points above U+00FF result in garbage whose nature must not be relied upon. (In the future the nature of the garbage will be CPU architecture-dependent.) If you want to printf() something and don't care what happens to non-ASCII, please convert to UTF-8 instead.
NS_LossyConvertUTF16toASCII(nsAString)- ansAutoCStringwhich holds a temporary buffer containing the Latin1 value of the string.LossyCopyUTF16toASCII(nsAString, nsACString)- does an in-place conversion from UTF-16 into an Latin1 string object.LossyAppendUTF16toASCII(nsAString, nsACString)- appends an UTF-16 string to an Latin1 string.ToNewCString(nsAString)- (avoid if ) allocates a new zero-terminated Latin1char*string.
Latin1 to UTF-16 converters
These converters are very dangerous because they will produce wrong results for non-ASCII UTF-8 or windows-1252 input into a meaningless UTF-16 string. You should avoid ASCII to UTF-16 conversions unless your strings are guaranteed to be ASCII or Latin1 in the sense of the byte value being the Unicode scalar value. Every byte is zero-extended into a 16-bit code unit.
It is correct to use these on most HTTP header values, but it's always wrong to use these on HTTP response bodies! (Use mozilla::Encoding to deal with response bodies.)
NS_ConvertASCIItoUTF16(nsACString)- ansAutoStringwhich holds a temporary buffer containing the value of the Latin1 to UTF-16 conversion.CopyASCIItoUTF16(nsACString, nsAString)- does an in-place conversion from Latin1 to UTF-16.AppendASCIItoUTF16(nsACString, nsAString)- appends a Latin1 string to a UTF-16 string.ToNewUnicode(nsACString)- (Avoid if possible) Creates a new zero-terminatedchar16_t*
Comparing ns*Strings with C strings
You can compare ns*Strings with C strings by converting the ns*String to a C string, or by comparing directly against a C String.
PromiseFlatCString(nsACString).get()- creates a temporarychar *out of a nsACString. This can be compared to a C String using C functions.ns*String.EqualsASCII(const char *)- compares with an ascii C string.ns*String.EqualsLiteral- compares with a string literal.
Common Patterns
Callee-allocated Parameters
Many APIs result in a method allocating a buffer in order to return strings to its caller. This can be tricky because the caller has to remember to free the string when they have finished using it. Fortunately, the getter_Copies() function makes this very easy.
A method may look like this:
void GetValue(char16_t** aValue)
{
*aValue = ToNewUnicode(foo);
}
Without getter_Copies(), the caller would need to free the string:
{
char16_t* val;
GetValue(&val);
if (someCondition) {
// don't forget to free the value!
NS_Free(val);
return NS_ERROR_FAILURE;
}
...
// and later, still don't forget to free!
NS_Free(val);
}
With getter_copies() you never have to worry about this. You can just use getter_Copies() to wrap a string class argument, and the class will remember to free the buffer when it goes out of scope:
{
nsString val;
GetValue(getter_Copies(val));
// val will free itself here
if (someCondition)
return NS_ERROR_FAILURE;
...
// and later, still nothing to free
}
The resulting code is much simpler, and easy to read.
Literal Strings
A literal string is a raw string value that is written in some C++ code. For example, in the statement printf("Hello World\n"); the value "Hello World\n" is a literal string. It is often necessary to insert literal string values when an nsAString or nsACString is required. Two user-defined literals are provided that implicitly convert to const nsString& resp. const nsCString&:
""_nsfor 8-bit literals, converting implicitly toconst nsCString&u""_nsfor 16-bit literals, converting implicitly toconst nsString&
The benefits of the user-defined literals may seem unclear, given that nsDependentCString will also wrap a string value in an nsCString. The advantage of the user-defined literals is that the length of these strings is calculated at compile time, so the string does not need to be scanned at runtime to determine its length.
Nowadays, all supported platforms have 16-bit literals using u""_ns, so we longer need to rely on macros for portability.
// call Init(const char16_t*) - bad signature, will need to do runtime length calculation inside
Init(L"start value"); // bad - L"..." is not portable!
Init(NS_ConvertASCIItoUTF16("start value").get()); // bad - runtime ASCII->UTF-16 conversion!
Init(u"start value"); // less bad, portable and no runtime conversion
// call Init(const nsAString&)
Init(nsDependentString(L"start value")); // bad - not portable!
Init(NS_ConvertASCIItoUTF16("start value")); // bad - runtime ASCII->UTF-16 conversion!
// call Init(const nsACString&)
Init(nsDependentCString("start value")); // bad - length determined at runtime
Here are some examples of proper usage of the literals (both standard and user-defined):
// call Init(const nsLiteralString&) - enforces that it's only called with literals
Init(u"start value"_ns);
// call Init(const nsAString&)
Init(u"start value"_ns);
// call Init(const nsACString&)
Init("start value"_ns);
In case a literal is defined via a macro, you can just convert it to nsLiteralString or nsLiteralCString using their constructor. You could consider not using a macro at all but a named constexpr constant instead.
In some cases, an 8-bit literal is defined via a macro, either within code or from the environment, but it can't be changed or is used both as an 8-bit and a 16-bit string. In these cases, you can use the NS_LITERAL_STRING_FROM_CSTRING macro to construct a nsLiteralString and do the conversion at compile-time.
String Concatenation
Strings can be concatenated together using the + operator. The resulting string is a const nsSubstringTuple object. The resulting object can be treated and referenced similarly to a nsAString object. Concatenation does not copy the substrings. The strings are only copied when the concatenation is assigned into another string object. The nsSubstringTuple object holds pointers to the original strings. Therefore, the nsSubstringTuple object is dependent on all of its substrings, meaning that their lifetime must be at least as long as the nsSubstringTuple object.
For example, you can use the value of two strings and pass their concatenation on to another function which takes an const nsAString&:
void HandleTwoStrings(const nsAString& one, const nsAString& two) {
// call HandleString(const nsAString&)
HandleString(one + two);
}
NOTE: The two strings are implicitly combined into a temporary nsString in this case, and the temporary string is passed into HandleString. If HandleString assigns its input into another nsString, then the string buffer will be shared in this case negating the cost of the intermediate temporary. You can concatenate N strings and store the result in a temporary variable:
constexpr auto start = u"start "_ns; constexpr auto middle = u"middle "_ns; constexpr auto end = u"end"_ns; // create a string with 3 dependent fragments - no copying involved! nsString combinedString = start + middle + end; // call void HandleString(const nsAString&); HandleString(combinedString);
It is safe to concatenate user-defined literals because the temporary nsLiteral[C]String objects will live as long as the temporary concatenation object (of type nsSubstringTuple).
// call HandlePage(const nsAString&); // safe because the concatenated-string will live as long as its substrings HandlePage(u"start "_ns + u"end"_ns);
Local variables
Local variables within a function are usually stored on the stack. The nsAutoString/nsAutoCString classes are derivatives of the nsString/nsCString classes. They own a 64-character buffer allocated in the same storage space as the string itself. If the nsAutoString is allocated on the stack, then it has at its disposal a 64-character stack buffer. This allows the implementation to avoid allocating extra memory when dealing with small strings. nsAutoStringN/nsAutoCStringN are more general alternatives that let you choose the number of characters in the inline buffer.
...
nsAutoString value;
GetValue(value); // if the result is less than 64 code units,
// then this just saved us an allocation
...
Member variables
In general, you should use the concrete classes nsString and nsCString for member variables.
class Foo {
...
// these store UTF-8 and UTF-16 values respectively
nsCString mLocalName;
nsString mTitle;
};
Note that the strings are declared directly in the class, not as pointers to strings. Don't do this:
class Foo {
public:
Foo() {
mLocalName = new nsCString();
mTitle = new nsString();
}
~Foo() { delete mLocalName; delete mTitle; }
private:
// these store UTF-8 and UTF-16 values respectively
nsCString* mLocalName;
nsString* mTitle;
};
The above code may appear to save the cost of the string objects, but nsString/nsCString are small objects - the overhead of the allocation outweighs the few bytes you'd save by keeping a pointer.
Another common incorrect pattern is to use nsAutoString/nsAutoCString for member variables. As described in Local Variables, these classes have a built in buffer that make them very large. This means that if you include them in a class, they bloat the class by 64 bytes (nsAutoCString) or 128 bytes (nsAutoString).
An example:
class Foo {
...
// bloats 'Foo' by 128 bytes!
nsAutoString mLocalName;
};
Raw Character Pointers
PromiseFlatString() and PromiseFlatCString() can be used to create a temporary buffer which holds a null-terminated buffer containing the same value as the source string. PromiseFlatString() will create a temporary buffer if necessary. This is most often used in order to pass an nsAString to an API which requires a null-terminated string.
In the following example, an nsAString is combined with a literal string, and the result is passed to an API which requires a simple character buffer.
// Modify the URL and pass to AddPage(const char16_t* url)
void AddModifiedPage(const nsAString& url) {
constexpr auto httpPrefix = u"http://"_ns;
const nsAString& modifiedURL = httpPrefix + url;
// creates a temporary buffer
AddPage(PromiseFlatString(modifiedURL).get());
}
PromiseFlatString() is smart when handed a string that is already null-terminated. It avoids creating the temporary buffer in such cases.
// Modify the URL and pass to AddPage(const char16_t* url)
void AddModifiedPage(const nsAString& url, PRBool addPrefix) {
if (addPrefix) {
// MUST create a temporary buffer - string is multi-fragmented
constexpr auto httpPrefix = u"http://"_ns;
AddPage(PromiseFlatString(httpPrefix + modifiedURL));
} else {
// MIGHT create a temporary buffer, does a runtime check
AddPage(PromiseFlatString(url).get());
}
}
printf and a UTF-16 string
For debugging, it's useful to printf a UTF-16 string (nsString, nsAutoString, etc). To do this usually requires converting it to an 8-bit string, because that's what printf expects. Use:
printf("%s\n", NS_ConvertUTF16toUTF8(yourString).get());
Sequence of appends without reallocating
SetCapacity() allows you to give the string a hint of the future string length caused by a sequence of appends (excluding appends that convert between UTF-16 and UTF-8 in either direction) in order to avoid multiple allocations during the sequence of appends. However, the other allocation-avoidance features of XPCOM strings interact badly with SetCapacity() making it something of a footgun.
SetCapacity() is appropriate to use before a sequence of multiple operations from the following list (without operations that are not on the list between the SetCapacity() call and operations from the list):
Append()AppendASCII()AppendLiteral()AppendPrintf()AppendInt()AppendFloat()LossyAppendUTF16toASCII()AppendASCIItoUTF16()
DO NOT call SetCapacity() if the subsequent operations on the string do not meet the criteria above. Operations that undo the benefits of SetCapacity() include but are not limited to:
SetLength()Truncate()Assign()AssignLiteral()Adopt()CopyASCIItoUTF16()LossyCopyUTF16toASCII()AppendUTF16toUTF8()AppendUTF8toUTF16()CopyUTF16toUTF8()CopyUTF8toUTF16()
If your string is an nsAuto[C]String and you are calling SetCapacity() with a constant N, please instead declare the string as nsAuto[C]StringN<N+1> without calling SetCapacity() (while being mindful of not using such a large N as to overflow the run-time stack).
There is no need to include room for the null terminator: it is the job of the string class.
Note: Calling SetCapacity() does not give you permission to use the pointer obtained from BeginWriting() to write past the current length (as returned by Length()) of the string. Please use either BulkWrite() or SetLength() instead.
IDL
The string library is also available through IDL. By declaring attributes and methods using the specially defined IDL types, string classes are used as parameters to the corresponding methods.
IDL String types
The C++ signatures follow the abstract-type convention described above, such that all method parameters are based on the abstract classes. The following table describes the purpose of each string type in IDL.
| IDL type | C++ Type | Purpose |
|---|---|---|
string |
char* |
Raw character pointer to ASCII (7-bit) string, no string classes used. High bit is not guaranteed across XPConnect boundaries. |
wstring |
|
Raw character pointer to UTF-16 string, no string classes used. |
AString |
nsAString |
UTF-16 string. |
ACString |
nsACString |
8-bit string. All bits are preserved across XPConnect boundaries. |
AUTF8String |
nsACString |
UTF-8 string. Converted to UTF-16 as necessary when value is used across XPConnect boundaries. |
DOMString |
nsAString |
UTF-16 string type used in the DOM. The same as AString with a few odd XPConnect exceptions: When the special JavaScript value null is passed to a DOMString parameter of an XPCOM method, it becomes a void DOMString. The special JavaScript value undefined becomes the string "undefined". |
C++ Signatures
In IDL, in parameters are read-only, and the C++ signatures for *String parameters follows the above guidelines by using const nsAString& for these parameters. out and inout parameters are defined simply as nsAString so that the callee can write to them.
| IDL | C++ |
|---|---|
interface nsIFoo : nsISupports {
attribute AString utf16String;
AUTF8String getValue(in ACString key);
};
|
class nsIFoo : public nsISupports {
NS_IMETHOD GetUtf16String(nsAString&
aResult) = 0;
NS_IMETHOD SetUtf16String(const nsAString&
aValue) = 0;
NS_IMETHOD GetValue(const nsACString& aKey,
nsACString& aResult) = 0;
};
|
In the above example, utf16String is treated as a UTF-16 string. The implementation of GetUtf16String() will use aResult.Assign to "return" the value. In SetUtf16String() the value of the string can be used through a variety of methods including Iterators, PromiseFlatString, and assignment to other strings.
In GetValue(), the first parameter, aKey, is treated as a raw sequence of 8-bit values. Any non-ASCII characters in aKey will be preserved when crossing XPConnect boundaries. The implementation of GetValue() will assign a UTF-8 encoded 8-bit string into aResult. If the this method is called across XPConnect boundaries, such as from a script, then the result will be decoded from UTF-8 into UTF-16 and used as a Unicode value.
Choosing a string type
It can be difficult to determine the correct string type to use for IDL. The following points should help determine the appropriate string type.
- Using string classes may avoid new memory allocation for
outparameters. For example, if the caller is using annsAutoStringto receive the value for anoutparameter, (defined in C++ as simplynsAString&then assignment of short (less than 64-characters) values to anoutparameter will only copy the value into thensAutoString's buffer. Moreover, using the string classes allows for sharing of string buffers. In many cases, assigning from one string object to another avoids copying in favor of simply incrementing a reference count. instrings using string classes often have their length pre-calculated. This can be a performance win.- In cases where a raw-character buffer is required,
stringandwstringprovide faster access thanPromiseFlatString. - UTF-8 strings defined with
AUTF8Stringmay need to be decoded when crossing XPConnect boundaries. This can be a performance hit. On the other hand, UTF-8 strings take up less space for strings that are commonly ASCII. - UTF-16 strings defined with
wstringorAStringare fast when the unicode value is required. However, if the value is more often ASCII, then half of the storage space of the underlying string may be wasted.
String Guidelines
Follow these simple rules in your code to keep your fellow developers, reviewers, and users happy.
- Use the most abstract string class that you can. Usually this is:
nsAStringfor function parametersnsStringfor member variablesnsAutoStringfor local (stack-based) variables
- Use the
""_nsandu""_nsuser-defined literals to represent literal strings (e.g."foo"_ns) as nsAString-compatible objects. - Use string concatenation (i.e. the "+" operator) when combining strings.
- Use
nsDependentStringwhen you have a raw character pointer that you need to convert to an nsAString-compatible string. - Use
Substring()to extract fragments of existing strings. - Use iterators to parse and extract string fragments.
Appendix A - What class to use when
This table provides a quick reference for what classes you should be using.
| Context | class | Notes |
|---|---|---|
| Local Variables | nsAutoString |
|
| Class Member Variables | nsString |
|
| Method Parameter types | nsAString |
Use abstract classes for parameters. Use const nsAString& for "in" parameters and nsAString& for "out" parameters. |
| Retrieving "out" string/wstrings | nsString |
Use getter_Copies(). Similar to nsString / nsCString. |
| Wrapping character buffers | nsDependentString |
Wrap const char* / const buffers. |
| Literal strings | nsLiteralString |
Similar to nsDependent[C]String, but pre-calculates length at build time. |
Appendix B - nsAString Reference
Read-only methods.
Length()IsEmpty()IsVoid()- XPConnect will convert void nsAStrings to JavaScriptnull.BeginReading(iterator)EndReading(iterator)Equals(string[, comparator])First()Last()CountChar()Left(outstring, length)Mid(outstring, position, length)Right(outstring, length)FindChar(character)
Methods that modify the string.
Assign(string)Append(string)Insert(string)Cut(start, length)Replace(start, length, string)Truncate(length)SetIsVoid(true)- Make it null. XPConnect will convert void nsAStrings to JavaScriptnull.BeginWriting(iterator)EndWriting(iterator)SetCapacity()- Inform the string about buffer size need before a sequence of calls to Append() or converting appends that convert between UTF-16 and Latin1 in either direction. (Don't use if you use appends that convert between UTF-16 and UTF-8 in either direction.) Calling this method does not give you permission to useBeginWriting()to write past the logical length of the string. UseSetLength()orBulkWrite()as appropriate.
Original Document Information
- Author: Alec Flett
- Copyright Information: Portions of this content are © 1998–2007 by individual mozilla.org contributors; content available under a Creative Commons license | Details.
- Thanks to David Baron for actual docs,
- Peter Annema for lots of direction
- Myk Melez for some more docs
- David Bradley for a diagram
- Revised by Darin Fisher for Mozilla 1.7
- Revised by Jungshik Shin to clarify character encoding issues